From scan to GPU-accelerated RL: causal contracts that train
Press a button, a lid opens. Pull a cord, the blinds rise. Twist a dial, the burner clicks on. These relationships are what we call causal contracts: authored rules that bind one joint's state to another's action. Every published system implements them the same way: Python callbacks that run fine in the editor. Load the same asset into GPU-accelerated RL training, where thousands of environments run simultaneously on the GPU, and the contracts go silent. The vectorized training step never calls those callbacks — Isaac Lab environments run as batched tensor operations on GPU with no per-environment Python execution context. The coupled object behaves as a bag of independent joints. The task becomes unlearnable.
We built the Realarity Contract Engine (CE), which turns authored causal contracts into batched tensor rules that run inside the training step, at zero throughput cost, across every environment simultaneously.
Where causal contracts break today
PhysX runs only hard constraints: joints, contacts, mimic, tendon. It has no execution model for conditional logic. Every published system handles this by placing the "if-then" above the solver, in Python. That works in single-environment playback. Under Isaac Lab's vectorized GPU training, it doesn't:
| Stack | Where causal contracts live | In GPU-accelerated training |
|---|---|---|
| ArtVIP (arXiv:2506.04941) | trigger-based coupling (omni.kit.scripting) | inert — only ticks with the editor running; validated at single-env scale only |
| OmniGibson / BEHAVIOR-1K | ObjectState._update() + TransitionRuleAPI.step() on CPU | per-env Python, scales linearly with environment count |
Hand-written torch.where | researcher inline, per task | does not generalise to a library |
We ran ArtVIP's microwave headless to confirm. Their trigger-based coupling never fired. The door stayed shut through every training iteration.
The Realarity Contract Engine
A causal contract specifies a trigger joint, a threshold, and an effect joint with a target. The Contract Engine reads that spec and emits a tensor rule that applies across all environments in a single GPU operation. No Python in the training step.
couplings.json → compile_bundle() → CompiledCouplings IR → CouplingTerm
│
batched tensor op every env-step
(loops only over the set of contracts)The restricted DSL is intentional. Restricting to joint-threshold triggers and set-drive-target effects is what makes vectorization possible. Anything outside the DSL surfaces in compiled.skipped with a reason rather than failing silently.
- Trigger:
joint_threshold— any joint, op<or>, threshold value - Effect:
set_drive_target— target joint, target value - Mode:
latchingorlevel
Integration into any DirectRLEnv is two lines:
class CoffeeTask(CompiledCouplingMixin, DirectRLEnv):
def _apply_action(self, actions):
targets = self.my_logic(actions)
self._art.set_joint_position_target(self.apply_couplings(targets))
def _reset_idx(self, ids):
super()._reset_idx(ids)
self.reset_couplings(ids)Throughput: the scaling wall
Per-env Python is not just slow — it is training-killing at the environment counts GPU-accelerated RL requires. Isolated coupling-layer step latency, 1k to 65k environments, RTX 5080:
| Envs | Per-env Python (ms/step) | CE (ms/step) | Speedup |
|---|---|---|---|
| 1,024 | 2.051 | 0.0134 | 153× |
| 65,536 | 132.521 | 0.0128 | 10,368× |
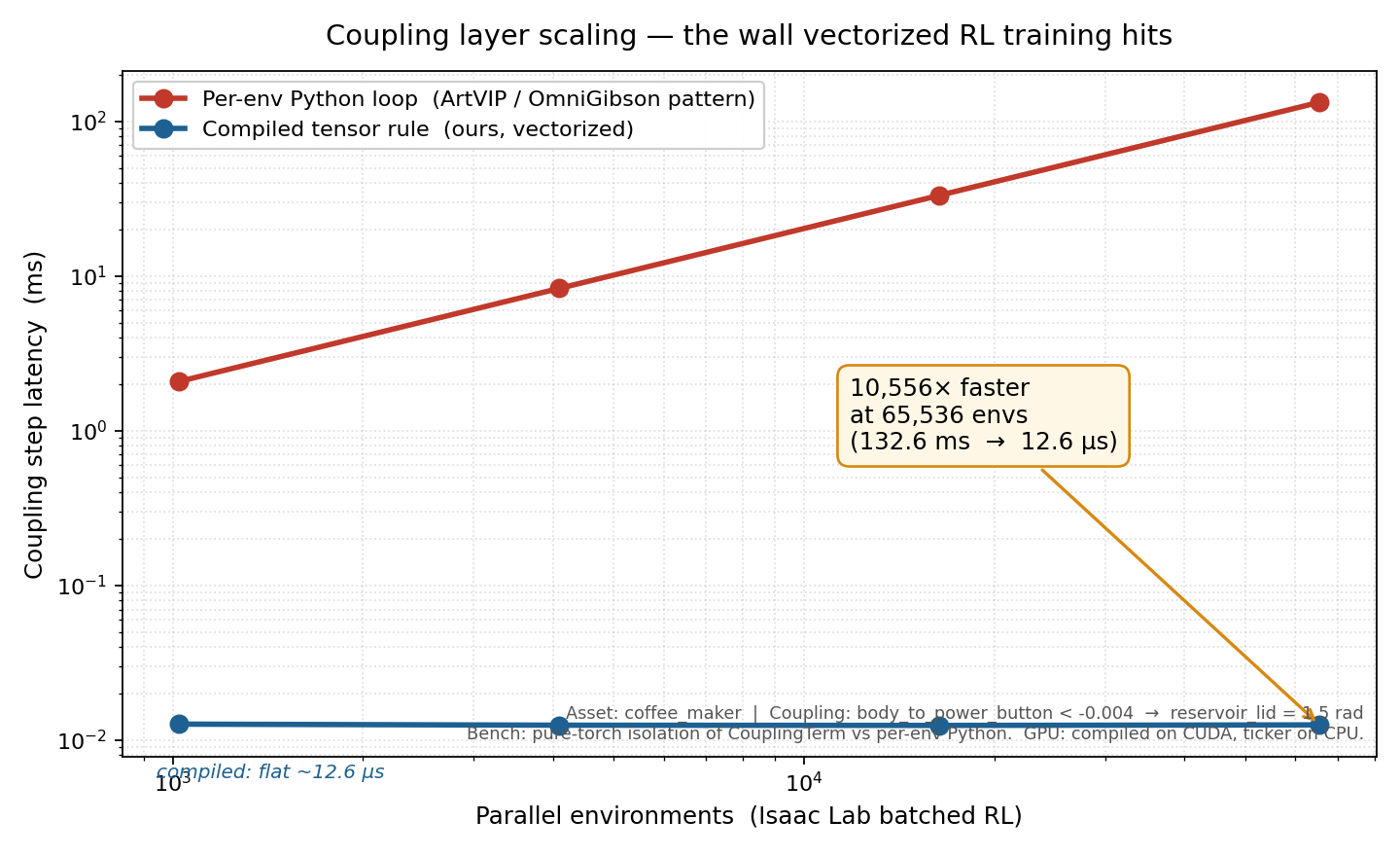
End-to-end Isaac Lab measurements inside a full PPO loop reach 56,000× at 65,536 environments. The 10,368× above is the isolated coupling-layer benchmark, which is easier to reproduce independently.
Learnability: the task that does not exist
Throughput is not the only failure mode. Even at small environment counts, a causal contract that does not fire produces a task the policy cannot learn from. To isolate this, we ran two PPO arms on ArtVIP's own microwave — 20 iterations each, same asset, same hyperparameters. The only difference was the coupling mechanism.
We measured effect | cause: of the environments where the button was pressed, what fraction saw the door open. This isolates the causal contract from the policy's press skill entirely.
| Iter | Native press | Native effect|cause | Native reward | CE press | CE effect|cause | CE reward |
|---|---|---|---|---|---|---|
| 1 | 0.609 | 0.00 | 0.00 | 0.875 | 1.00 | 1.00 |
| 5 | 1.000 | 0.00 | 0.00 | 0.922 | 1.00 | 1.00 |
| 10 | 1.000 | 0.00 | 0.00 | 0.969 | 1.00 | 1.00 |
| 20 | 1.000 | 0.00 | 0.00 | 1.000 | 1.00 | 1.00 |
By iteration 5, the native arm has learned to press the button on every step. The door never opens. Reward stays at zero. The policy has nothing to learn from because the causal contract that should connect the press to the door is inert. The CE arm receives a reward gradient from iteration 1.
The same Contract Engine, applied to three separate assets across two operator types and two trigger joint types, passed the training gate on all three: coffee maker button-to-lid (open_frac 1.00), ArtVIP microwave button-to-door (0.91, with a small number of NaN environments from recon instability), and a scanned car where opening the boot triggers the rear hatch (1.00). Each result written to a
coupling_training_report.jsonper asset.
End-to-end: causal contracts inside the training loop
To close the loop, we ran skrl-2.0 PPO on a coffee maker with the compiled contract active throughout training. Action: button press. Reward: lid openness. Causal contract applied each step in _apply_action, latch cleared in _reset_idx.
- Scripted sanity: 256/256 lids open on press, return to closed on reset
- After 4,000 PPO steps: trained policy presses, compiled contract opens lid, 256/256 environments, eval reward 0.98
The contract is not playback. It is not a demo. It runs inside the training loop, across every environment, for the duration of training.
Current scope
The DSL boundary is the design, not a limitation to be removed. What falls outside it today:
- Soft bodies, fluids, deformables — outside the joint-motion class the DSL covers
- Other simulator backends — Isaac Lab only in v0.1; the IR is gym-agnostic
- Cross-asset contracts at training scale — intra-articulation today
- Sim-to-real fidelity of the contract — the Contract Engine faithfully reproduces the authored spec in sim; correspondence to the physical device depends on calibration
- Real-robot transfer — a separate pipeline stage, not addressed here
What this enables at scale
Our reconstruction pipeline produces a structured couplings.json for every asset it generates. Because that spec is consistent and typed, the Contract Engine processes it without per-asset engineering. One CE run, any asset that fits the DSL, training-ready output.
At dataset scale, this is the difference between a library of coupled assets that can be trained on and one that cannot. A hand-authored per-object Python script cannot be compiled to a tensor rule. A structured spec can. The Contract Engine is what connects our asset pipeline to GPU-accelerated RL at the other end.
The broader context is Realm, the neural translation layer the Contract Engine feeds into. Get in touch if articulated manipulation at training scale is a problem you are working on.