The proving layer
The sim-to-real gap is not a policy problem. It is a fidelity problem. Veron is the training and calibration layer that closes it: orchestrating simulation environments against Realm-qualified physics, classifying failures deterministically, and routing corrections back to the responsible parameter. Each run starts closer to reality than the last.
Veron is a training and deployment SDK for Physical AI. It orchestrates Isaac Lab; it does not replace it. Point it at Realm-qualified environments, define your task and robot, and run multi-variant training: calibrated physics as the baseline, domain randomisation to stress-test robustness across configurations. Runs converge. You build real confidence in simulation before anything touches hardware.
When you deploy, the Veron SDK follows the robot into the field. It tracks every run against what simulation predicted: force-torque, trajectories, contact geometry. When the real world diverges from simulation, Veron records the discrepancy as a structured calibration event, routes it deterministically to the responsible parameter, and applies the correction. The next training run starts from better physics.
Simulation orchestration
Veron loads qualified assets from Realm and spawns training environments in Isaac Lab. Domain randomisation is available but not the default; Veron prefers calibrated physics because randomisation masks the exact failures that matter. Variants run against calibrated physics first; randomisation tests robustness once the baseline holds.
Every run is tracked to its source asset version. If a training run used lighter_v3 at commit a3f8e1, that provenance is recorded. When the asset updates, Veron knows which policies were trained against stale physics and which are current.
Lighter asset loaded in Isaac Lab: geometry, physics, and articulation ready for training.
# 1. Train against calibrated physics — 64 vectorized Isaac Lab envs.
# coffee_maker_v3 resolves from your Realm registry.
veron train coffee_maker_v3 --num-envs 64
# 2. Deploy in the test environment. Records per-trial DNA:
# observed friction, applied torque, travel reached.
veron sim-deploy coffee_maker_v3 --aff open_reservoir_lid \
--friction-scale 2.0 --trials 10
# 3. Route the failure. Patches the responsible parameter and
# emits an append-only audit ticket.
veron calibrate coffee_maker_v3 --aff open_reservoir_lid \
--dna out/sim_deploy/dna.json --route-failure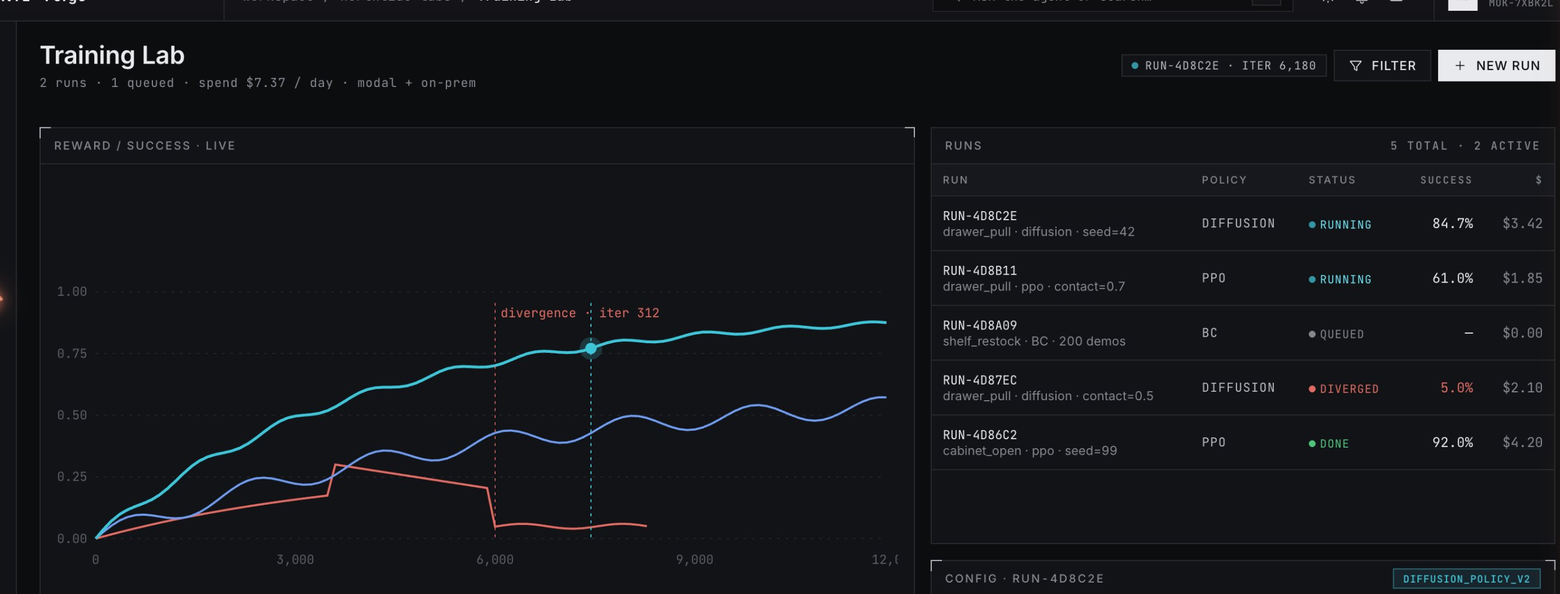
Training Lab concept: reward curves across concurrent training runs.
Structured correction
When a run fails, Veron does not wait for an engineer to read a log. It classifies the failure, routes the correction to the responsible component, and queues the appropriate action. Each failure produces a typed correction record: what failed, what was observed versus expected, the confidence of that observation, and what to fix. Every correction is append-only and traceable back to the run that produced it.
The classification is deterministic. An LLM handles the user-facing interface only: translating correction records into plain English and accepting task descriptions in plain English. It has no role in the routing decision itself.
The proof
A coffee maker. Task: open the reservoir lid. A sim-to-sim test: the “real world” was a second Isaac Sim environment with a deliberate friction mismatch (lid hinge friction at twice the calibrated value) standing in for real-world divergence from simulation.
Baseline: 2 from 20. The robot could not reliably complete the task. Veron classified the failure, routed it to the responsible parameter, and applied the correction: hinge friction patched from 3.2 to 6.311, recorded as audit ticket TKT-98dd5093.
Post-correction: 10 from 10. Faithfulness score (how closely outcomes in the test environment match simulation predictions) moved from 0.00 to 0.97.
The fix was not guessed. It was routed deterministically from the failure signal to the parameter responsible.
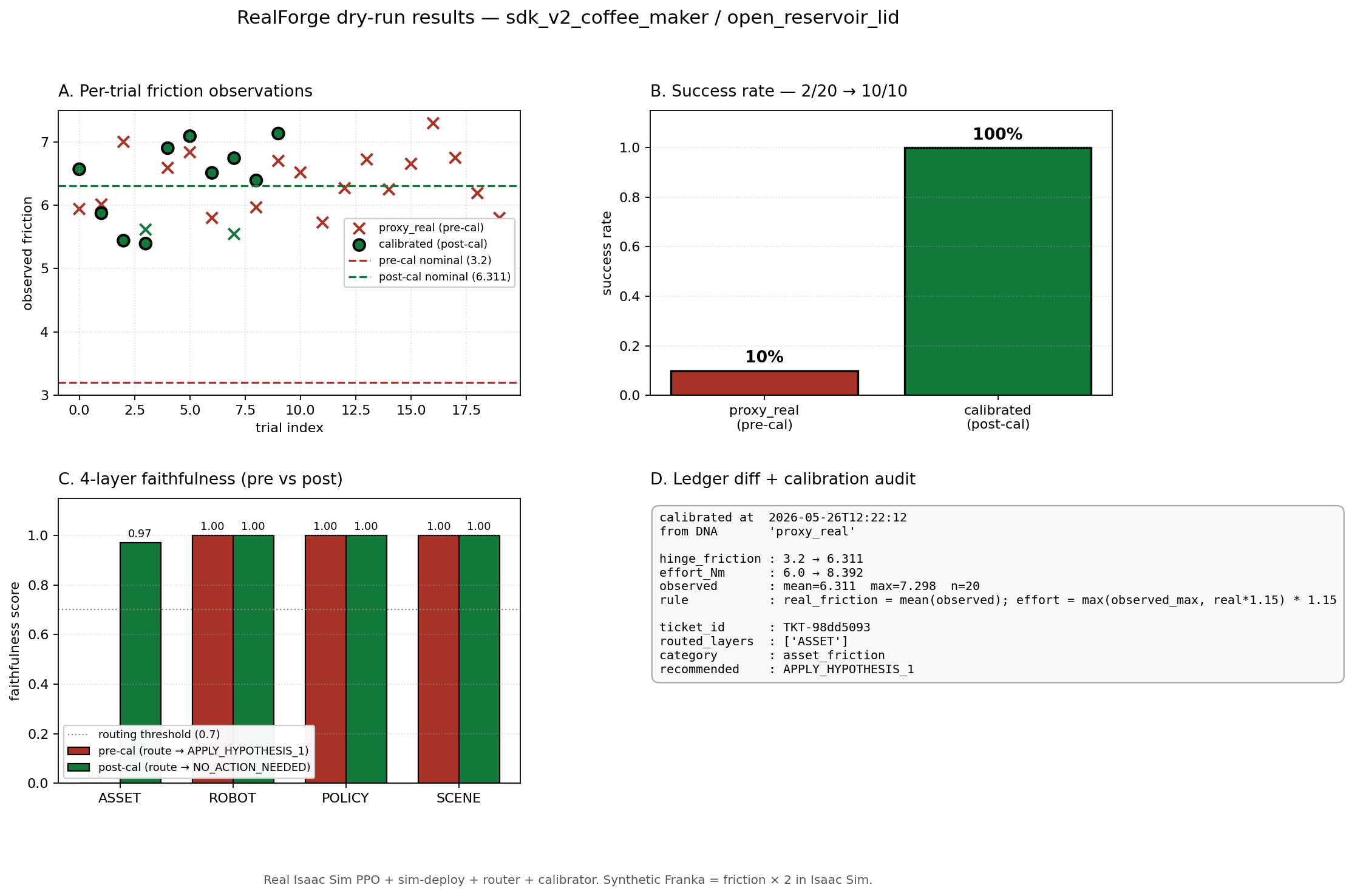
The full audit: per-trial friction observations, success rate 2/20 → 10/10, four-layer faithfulness, and the ledger diff with its ticket ID.
Continuous calibration
Structured correction handles individual failures. Continuous calibration is what happens across runs. Every time Veron surfaces a physics mismatch and records it as a calibration event, that observation accumulates. Successive training runs start from progressively more accurate physics, not from the same initial approximation every time.
Franka arm with the lighter asset in Isaac Lab.
A lighter with a spring-loaded trigger has physics that matter: trigger resistance, safety lock friction, nozzle alignment. When a training run surfaces a divergence between simulation and physical reality, that observation is recorded as a calibration event. The next run incorporates it. Physics parameters converge toward real-world values across successive runs.
The real-world loop
Simulation calibration is the first loop. The second is harder: getting real-world deployment signals back into Veron in a structured way.
When a policy deploys to a real robot, the Veron SDK tracks the run against what simulation predicted: force-torque readings, end-effector trajectories, grasp events, contact geometry. When the robot fails, those signals flow back into Veron. The same classification logic runs. Corrections are routed to the responsible component: object physics updated, retraining queued, hardware issues flagged, new environments requested.
Each deployment cycle returns structured evidence to both the policy and the simulation it trained in. Physics parameters that diverged from reality are corrected. Teams onboarding an asset with an existing deployment history start from a more accurate baseline than the first team that deployed it.
The hard problem is ingestion: parsing structured sensor data from heterogeneous robot stacks into typed calibration signals without requiring every team to build a custom integration. This is the frontier of what we are building. The routing logic downstream is defined. What we are solving now is the transport.
Status
| Component | Status | Detail |
|---|---|---|
| Simulation orchestration | Working | Isaac Lab integration, vectorized rollouts (64-env training gate), asset provenance tracking |
| Failure classification | Working | Deterministic failure routing. Validated on coffee maker dry run: faithfulness 0.00 → 0.97 |
| Calibration schema | Working | Typed, versioned. Validated on coffee maker and toilet seat assets |
| Continuous calibration (sim) | Working | Sim-to-sim calibration loop demonstrated end-to-end |
| Deployment signal ingestion | In development | Standardised sensor log parsing across robot stacks |
| Real-world calibration loop | In development | End-to-end from hardware deployment back to simulation fidelity |
Veron is the point where simulation fidelity is validated against real-world outcomes. Every run is versioned and traceable. Every failure produces a structured correction with a defined action. Successive deployments converge toward accurate physics.
Get in touch to explore Veron.